Travailler son référencement ChatGPT ne se résume pas à optimiser ses balises pour un nouveau moteur. L’IA générative ne fonctionne pas comme Google : elle ne classe pas dix résultats, elle synthétise une réponse à partir de sources qu’elle juge fiables, parfois sans même les indexer récemment. Comment fait-on entrer son site dans ce nouveau jeu, où la citation pèse autant que le clic ?
Référencement ChatGPT : de quoi parle-t-on exactement ?
Le référencement ChatGPT désigne l’ensemble des actions techniques et éditoriales qui rendent une marque ou un site visible dans l’écosystème ChatGPT. Il couvre deux mécaniques distinctes : ChatGPT Search, qui affiche des sources cliquables comme un moteur classique, et le mode génératif, qui synthétise une réponse à partir des connaissances du modèle. Double objectif : faire citer sa marque dans les réponses, et faire apparaître son site dans les sources proposées aux utilisateurs.
Un article positionné en page 1 sur Google peut très bien rester invisible dans ChatGPT, et inversement. Les signaux se recoupent en partie, mais l’IA pondère différemment l’autorité de marque, les entités et les sources tierces. Optimiser pour ChatGPT impose une stratégie dédiée qui peut être pilotée par une agence spécialisée en GEO.
Différence entre référencement classique, GEO et AEO
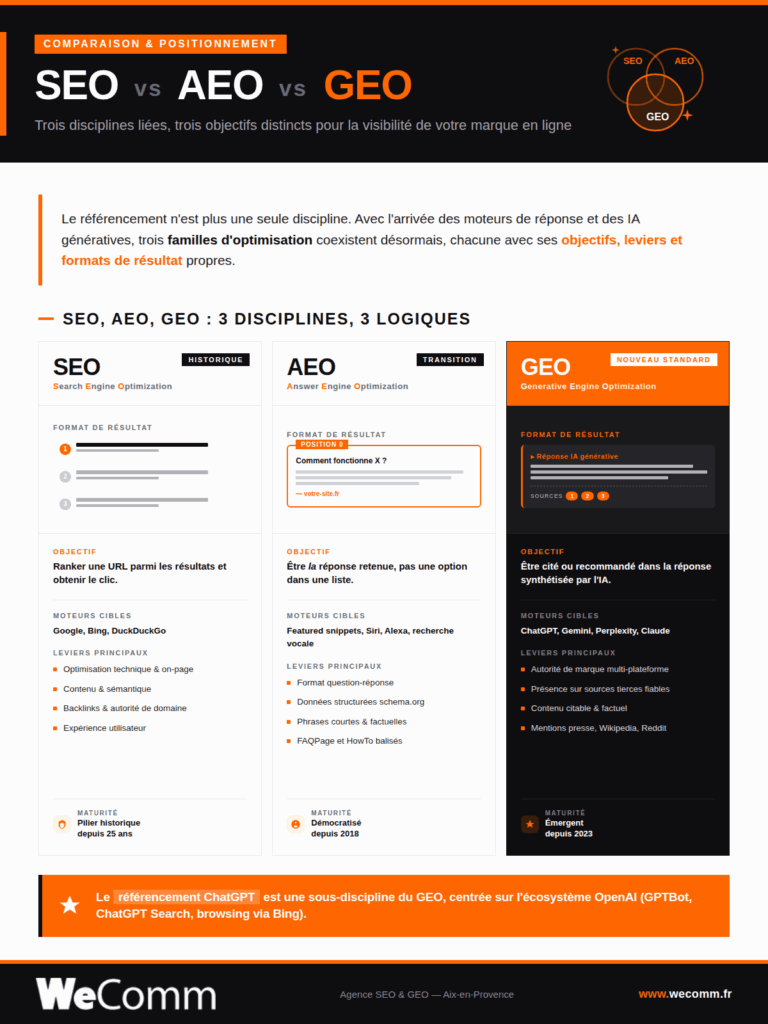
Trois disciplines liées mais aux objectifs distincts.
- SEO (Search Engine Optimization) : optimiser un site pour Google ou Bing. L’objectif reste de ranker une URL sur une page de résultats, avec un clic à la clé. Leviers historiques : technique, contenu, backlinks, expérience utilisateur.
- AEO (Answer Engine Optimization) : optimiser pour les moteurs de réponse qui affichent un résultat unique. Featured snippets, position zéro, recherche vocale, assistants comme Siri ou Alexa. Le but : être la réponse retenue, pas une option dans une liste. Format question-réponse, données structurées et phrases courtes deviennent décisifs.
- GEO (Generative Engine Optimization) : optimiser pour les moteurs génératifs comme ChatGPT, Gemini, Perplexity ou Claude. L’IA ne classe pas, elle synthétise. Le levier principal devient l’autorité de marque et la présence sur des sources tierces fiables, pas seulement le rang sur Google.
Le référencement ChatGPT est une sous-discipline du GEO, centrée sur l’écosystème OpenAI et ses spécificités techniques (GPTBot, ChatGPT Search, intégration Bing pour le browsing). « Pour une vue d’ensemble des acronymes du référencement IA, voir notre glossaire.
Pourquoi ça compte maintenant
ChatGPT a franchi les 800 millions d’utilisateurs hebdomadaires en 2025, et une partie croissante des requêtes informationnelles ne passe plus jamais par Google. L’utilisateur pose sa question, lit la réponse synthétique, ferme l’onglet. Pour les sites qui vivaient du trafic info, l’équation a changé.
Quatre raisons d’agir maintenant :
- Le trafic informationnel migre vers les IA. Les requêtes « comment faire X », « différence entre A et B », « meilleur outil pour Y » sont absorbées par ChatGPT, Perplexity et Gemini. Les études Similarweb, Ahrefs et BrightEdge convergent : baisse du CTR organique, hausse de la part des IA dans la découverte d’informations.
- ChatGPT Search rebat les cartes du SEO classique. Le moteur dispose de son propre crawler (OAI-SearchBot), de ses propres critères de fraîcheur et s’appuie largement sur l’index Bing. Invisible de Bing = invisible de ChatGPT Search.
- La citation devient un actif marketing. Être cité par une IA sur une requête commerciale (« meilleure agence SEO à Aix-en-Provence ») impacte la notoriété même sans clic. Et les IA renforcent leurs propres choix : plus une source est citée, plus elle a de chances d’être recitée.
- L’écart se creuse entre ceux qui mesurent et les autres. Les premiers acteurs à tracker leurs KPIs GEO (mention, citation, Share of Voice) itèrent pendant que les autres avancent à l’aveugle.
Le référencement ChatGPT n’est plus un nice-to-have. C’est un canal d’acquisition mesurable, dont le coût d’entrée augmente chaque mois.
Comment ChatGPT trouve et utilise vos contenus
ChatGPT n’est pas un moteur unique mais une stack de plusieurs systèmes. Quatre mécanismes à comprendre avant d’optimiser.
ChatGPT Search
Module de browsing temps réel déclenché sur les requêtes d’actualité, locales ou nécessitant des données fraîches. ChatGPT lit les pages web et synthétise une réponse avec sources cliquables.
- L’index principal vient de Bing. Si Bing ne connaît pas votre site, ChatGPT Search non plus. Soumettre son sitemap à Bing Webmaster Tools redevient indispensable.
- OAI-SearchBot crawle en parallèle. Crawler propre à OpenAI, distinct de GPTBot, qui enrichit l’index Bing.
- Les citations sont cliquables et trackables. Trafic direct mesurable dans les analytics avec le referrer chatgpt.com.
Le corpus d’entraînement
La connaissance « gelée » du modèle, figée à une date de cutoff. Une marque devient connue du modèle quand elle apparaît suffisamment dans des sources fiables, avec des associations sémantiques cohérentes.
- Une mention Wikipedia pèse bien plus qu’un communiqué de presse low-cost.
- Présence répétée sur la presse spécialisée, Reddit, Stack Overflow, annuaires institutionnels = entité solide.
- Cohérence du nom, de la description et du secteur à travers les sources = confiance renforcée.
Certaines marques répondent à « meilleure agence SEO à Aix-en-Provence » sans qu’aucun crawler n’ait visité leur site récemment : le modèle les a apprises pendant l’entraînement.
Fine-tuning, RLHF et retrieval augmenté
Trois couches qui modifient le comportement du modèle entre le corpus brut et la réponse finale.
- Fine-tuning : ajustement sur des jeux de données spécifiques.
- RLHF : des humains notent les réponses, ce qui survalorise les sources jugées fiables par les annotateurs.
- RAG : injection à la volée de documents récents (Search, fichiers, mémoire) dans le contexte de la réponse.
Conséquence : une marque peut être citée sans crawl récent si elle est ancrée dans le corpus, et un site fraîchement crawlé peut rester invisible si l’entité de marque n’est pas reconnue.
Être cité ≠ être positionné
La confusion la plus fréquente. Le référencement ChatGPT poursuit deux objectifs distincts qui demandent des leviers différents.
| Objectif | Mécanisme | Levier principal | Mesure |
| Être positionné (source cliquable) | Crawl + index Bing/OAI-SearchBot | SEO technique, contenu LLM-friendly, backlinks | Apparitions sources, trafic referrer |
| Être cité (mention générée) | Corpus + RLHF + RAG | Autorité de marque, sources tierces, entités | Taux de mention, Share of Voice |
Une stratégie complète couvre les deux : un site bien indexé mais jamais cité laisse partir la moitié de la valeur, une marque citée mais mal indexée laisse fuir le trafic vers des concurrents mieux positionnés.
Comment être cité par ChatGPT : la méthode complète
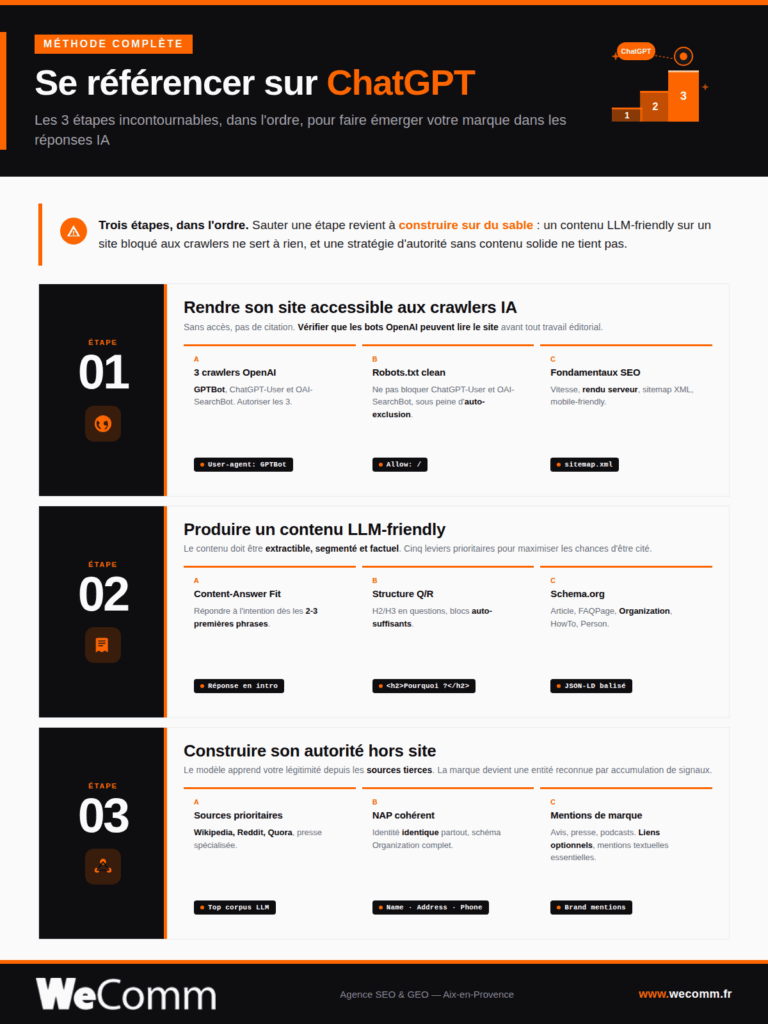
Trois étapes, dans l’ordre. Sauter une étape revient à construire sur du sable : un contenu LLM-friendly sur un site bloqué aux crawlers ne sert à rien, et une stratégie d’autorité sans contenu solide ne tient pas.
Étape 1 : rendre son site accessible aux crawlers IA
Avant tout travail éditorial, vérifier que les bots ont le droit et la possibilité d’accéder au site. Trois crawlers OpenAI à connaître, avec des rôles différents.
| User-agent | Rôle | À autoriser ? |
| GPTBot | Crawl pour l’entraînement des futurs modèles | Oui (sauf raison spécifique) |
| ChatGPT-User | Récupération à la volée quand un utilisateur pose une question liée à votre site | Oui, impératif |
| OAI-SearchBot | Indexation pour ChatGPT Search | Oui, impératif |
- Configuration robots.txt. La règle pragmatique : autoriser les trois sauf si vous avez une raison commerciale forte de bloquer GPTBot (contenu premium, position de principe sur l’IA). Bloquer ChatGPT-User et OAI-SearchBot revient à se couper volontairement de l’écosystème.
- Le débat llms.txt. Proposé en 2024, ce fichier devait servir de plan structuré du site pour les LLM. En 2026, l’adoption reste marginale : OpenAI, Anthropic et Google ne l’utilisent pas officiellement comme signal de ranking. Le mettre en place coûte peu, mais ne pas en attendre d’effet mesurable. Priorité aux sitemaps XML classiques.
- Les fondamentaux techniques restent décisifs. Vitesse de chargement, rendu serveur ou pré-rendu pour les sites JS lourds, sitemap XML à jour, balises meta propres, accessibilité mobile. Les LLM ne crawlent pas mieux que Googlebot : un site lent ou mal rendu sera mal indexé partout.
Étape 2 : produire un contenu LLM-friendly
Une fois l’accès garanti, le contenu doit être rédigé et structuré pour que les LLM puissent l’extraire, le comprendre et le citer. Cinq leviers prioritaires.
- Content-Answer Fit. Répondre à l’intention dès les 2-3 premières phrases du contenu, avant tout développement. Les LLM extraient en priorité les passages qui formulent une réponse claire à une question implicite. Une intro qui tourne autour du sujet sans répondre = contenu invisible dans les citations.
- Structure question-réponse. Multiplier les H2 et H3 formulés en questions, suivis d’une réponse synthétique. Les FAQ en bas d’article ne suffisent plus : l’ensemble du contenu gagne à être segmenté en blocs auto-suffisants, chacun répondant à une sous-intention.
- Entités plutôt que mots-clés. Les LLM raisonnent en entités (personnes, lieux, marques, concepts) reliées entre elles, pas en occurrences de mots-clés. Citer explicitement les entités de référence du sujet, lier à leurs pages Wikipedia ou institutionnelles, et structurer le contenu autour d’un graphe de concepts cohérent renforce la compréhension du modèle.
- Données structurées prioritaires. Le balisage Schema.org reste un signal fort, à la fois pour Bing et pour les LLM qui exploitent ces données pour l’extraction. À implémenter en priorité :
- Article ou BlogPosting sur tout contenu éditorial
- FAQPage sur les blocs Q/R
- Organization complet (logo, sameAs, fondateur, adresse)
- Product et Review sur les fiches produit
- HowTo sur les guides étape par étape
- Person pour l’auteur, avec bio et expertise
- Fraîcheur et dates visibles. Afficher une date de publication et une date de dernière mise à jour dans le HTML (et dans les données structurées). Les LLM pondèrent fortement la fraîcheur sur les sujets sensibles à l’actualité. Mettre à jour un article ancien avec une nouvelle date a souvent plus d’impact que d’en publier un nouveau.
Étape 3 : construire son autorité hors site
Le contenu sur votre site ne suffit pas à faire de votre marque une entité reconnue. Le modèle apprend votre légitimité depuis les sources tierces. Cinq chantiers à mener en parallèle.
- Présence sur les sources que les LLM citent en priorité. Wikipedia (page d’entreprise si critères de notoriété atteints, sinon mentions dans des articles existants), Reddit et Quora (réponses expertes signées, sans spam), presse spécialisée du secteur, sites institutionnels (CCI, syndicats professionnels, annuaires officiels). Une mention sur ces plateformes pèse dix fois plus qu’un backlink low-cost.
- Backlinks IA de qualité. Toujours utiles, parce qu’ils alimentent l’autorité Bing donc ChatGPT Search, et qu’ils signalent au modèle les associations entre votre marque et son secteur. Privilégier la pertinence thématique au volume.
- Cohérence NAP et schéma Organization. Nom, adresse, téléphone identiques partout (site, Google Business Profile, Bing Places, annuaires). Le schéma Organization complet sur le site (logo, sameAs vers tous vos profils sociaux et institutionnels, founder, foundingDate) verrouille l’identité de la marque aux yeux du modèle.
- Avis et UGC. Les avis Google, Trustpilot, secteurs spécialisés (Doctolib pour le médical, Tripadvisor pour le tourisme) nourrissent le corpus. Les LLM lisent les avis comme un signal de réputation GEO. Pas de triche : les modèles détectent les patterns de faux avis.
- Mentions de marque non liées. Une mention textuelle de votre marque dans un article, même sans lien, est lue par le modèle. La presse, les podcasts (transcrits), les YouTube avec descriptions textuelles, les newsletters publiées en ligne : tout texte indexé alimente l’apprentissage.
L’objectif global de cette étape : faire en sorte qu’à la question « qui sont les acteurs sérieux de [votre secteur] dans [votre zone] », votre marque apparaisse de manière récurrente sur des sources que le modèle juge fiables. C’est ce qui transforme une présence ponctuelle en citation durable.
Mesurer son référencement ChatGPT
On ne pilote pas ce qu’on ne mesure pas. C’est valable pour le SEO classique, ça l’est encore plus pour le référencement ChatGPT, où les signaux sont moins visibles et où les Search Consoles n’existent pas (encore). Sans tracking dédié, impossible de savoir si une publication, un backlink ou une mise à jour produit un effet réel.
Les 3 KPIs GEO à suivre
- Taux de mention : Pourcentage de prompts d’un panel pour lesquels votre marque est citée dans la réponse, sous n’importe quelle forme (nom, URL, lien). C’est le KPI de notoriété pure : votre marque existe-t-elle dans la tête du modèle ?
- Taux de citation : Pourcentage de prompts pour lesquels votre site est listé comme source cliquable (mode Search). Ce KPI mesure votre positionnement technique, pas votre autorité. Un site bien indexé mais sans autorité de marque aura un bon taux de citation et un mauvais taux de mention.
- Share of Voice (SoV) : Part de vos mentions sur l’ensemble des mentions de marques (vous + concurrents) sur un panel de prompts. C’est le KPI compétitif : sur 100 réponses contenant une marque de votre secteur, combien vous citent vous plutôt qu’un concurrent. Un SoV qui monte = vous gagnez du terrain. Un SoV qui stagne pendant que le taux de mention monte = tout le marché grossit, vous suivez la vague.
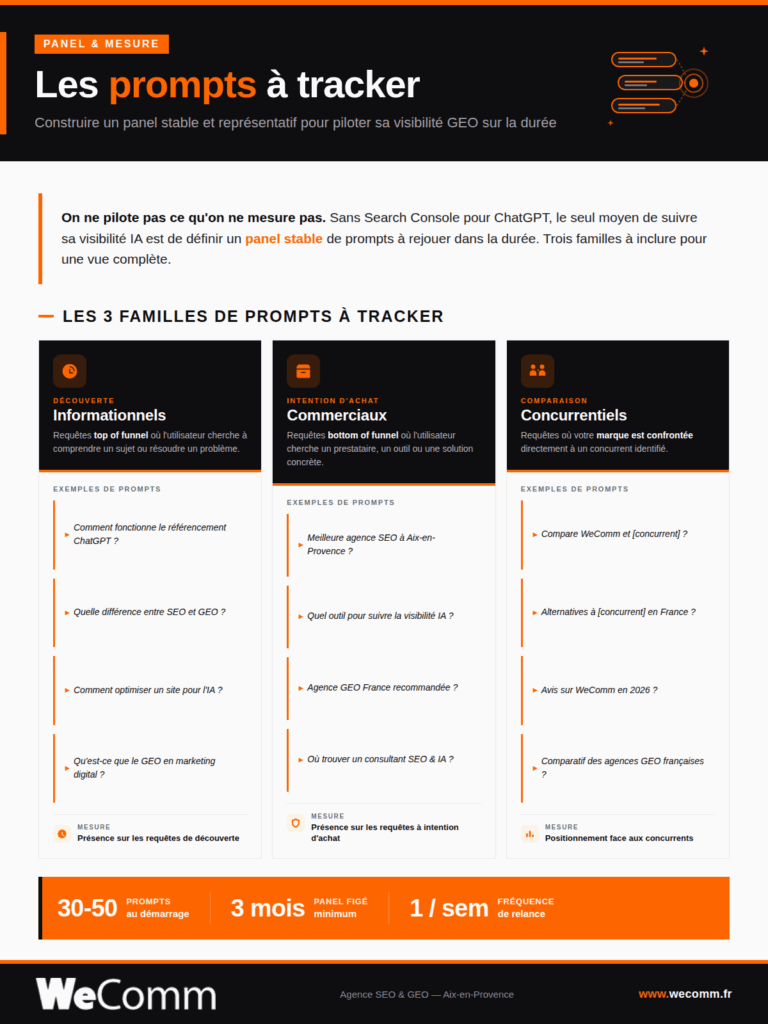
Définir un panel de prompts cibles
Le panel est la base de toute mesure GEO. Sans panel stable et représentatif, les variations mesurées ne veulent rien dire. Trois familles à inclure :
- Prompts informationnels. « Comment fonctionne le référencement ChatGPT », « différence entre SEO et GEO », « comment optimiser un site pour l’IA ». Mesurent votre présence sur les requêtes de découverte.
- Prompts commerciaux. « Meilleure agence SEO à Aix-en-Provence », « quel outil pour suivre la visibilité IA », « agence GEO France ». Mesurent votre présence sur les requêtes à intention d’achat.
- Prompts concurrentiels. « Comparaison entre [vous] et [concurrent] », « alternatives à [concurrent] », « avis sur [vous] ». Mesurent votre positionnement face à un concurrent identifié.
Compter 30 à 50 prompts pour démarrer, à figer pendant au moins un trimestre pour observer des évolutions exploitables. Les rejouer chaque semaine ou chaque mois selon la criticité.
Méthode manuelle vs outils automatisés
- Manuel : Lancer chaque prompt à la main, dans une session déconnectée, copier les réponses dans un tableur, taguer les mentions. Faisable pour 10-15 prompts, ingérable au-delà. Et le bruit est important : ChatGPT renvoie des réponses différentes pour le même prompt selon la session et le contexte.
- Outils automatisés : Plusieurs solutions sont apparues en 2025-2026 pour automatiser la collecte. Elles tournent les prompts en boucle via API ou navigation headless, agrègent les réponses, taguent automatiquement les mentions et calculent les KPIs sur la durée.
L’outil n’est pas la stratégie : un bon dashboard sans plan d’action ne fait rien bouger. Mais sans mesure, le plan d’action avance à l’aveugle.
Itérer après chaque action
Le but du tracking, c’est d’identifier les leviers qui fonctionnent vraiment sur votre secteur, pas de produire un joli rapport. Concrètement :
- Publier un article pilier sur un sujet → mesurer 2-4 semaines plus tard si les prompts liés citent davantage votre marque ou votre URL.
- Obtenir un backlink ou une mention sur une source à forte autorité → vérifier l’impact sur le taux de mention dans les 4-8 semaines.
- Mettre à jour une page ancienne avec dates fraîches et données structurées renforcées → mesurer si la page passe de citée à non citée, ou inversement.
- Comparer le SoV avant et après une campagne RP ou un partenariat presse.
Cette boucle mesure → action → mesure est ce qui sépare une stratégie GEO efficace d’un empilement de bonnes pratiques sans résultat vérifié.
Les erreurs fréquentes en référencement ChatGPT
Cinq erreurs reviennent régulièrement, indépendamment du secteur et de la taille du site. Aucune n’est compliquée à corriger, mais chacune peut suffire à bloquer une stratégie entière.
Bloquer GPTBot par réflexe
L’erreur la plus coûteuse. Beaucoup de sites ont bloqué GPTBot par principe en 2023-2024, se coupant de l’apprentissage du modèle et des futures citations. La décision dépend du modèle économique : un média payant peut le justifier, un site de marque a tout intérêt à laisser passer. Dans tous les cas, ne jamais bloquer ChatGPT-User ni OAI-SearchBot, qui servent à l’affichage en temps réel.
Publier du contenu IA générique non révisé
Les contenus IA non revus sont mal cités par les IA elles-mêmes. Les LLM détectent les patterns d’écriture générique (formulations vides, absence d’angle) et les pondèrent négativement. Un article qui ressemble à 10 000 autres n’apporte rien au modèle, qui préfère les sources avec une voix, des chiffres et un point de vue identifiable. L’IA est un assistant de production, pas un substitut.
Tout miser sur les mots-clés en oubliant l’entité de marque
Les LLM raisonnent en entités, pas en mots-clés. Un article bien optimisé sur « référencement ChatGPT » sans travail sur l’identité de marque ne sera pas associé à votre marque dans la mémoire du modèle. Vérifier systématiquement le balisage Schema (auteur, organisation), la cohérence sémantique du cluster et les mentions externes qui confirment l’association.
Oublier les sources tierces
Trop d’équipes concentrent 100 % de leurs efforts sur leur propre site. Le modèle apprend votre marque depuis Wikipedia, Reddit, la presse et les annuaires. Si vous n’existez pas hors de votre site, vous existez peu pour ChatGPT. Sur les premiers mois, viser un ratio 50/50 entre on-site et off-site, contre 70/30 en SEO classique.
Ne pas mesurer
Sans mesure, tout devient une affaire de croyance. On publie, on attend, on espère. Les marques qui prennent une avance durable définissent un panel de prompts, suivent leurs trois KPIs, et réajustent chaque mois. L’absence de tracking finance des actions inefficaces qu’on aurait pu arrêter plus tôt.
Le référencement ChatGPT en 3 décisions
Le référencement ChatGPT n’est plus une discipline expérimentale. Les mécaniques sont connues, les leviers identifiés, les outils de mesure existent. Trois décisions opérationnelles séparent les marques visibles des autres.
La première, travailler les deux fronts en parallèle. Être positionné dans Search demande un SEO technique propre et un index Bing à jour. Être cité dans les réponses génératives demande une autorité de marque construite hors site. Les deux se complètent, ne se substituent pas.
La deuxième, publier moins mais mieux. Les contenus génériques sont ignorés par les IA elles-mêmes. Un article signé, avec un angle clair et des données propriétaires, pèsera plus qu’une dizaine de pages neutres. La ligne éditoriale redevient un actif stratégique.
La troisième, mesurer dès le premier jour. Sans panel de prompts ni suivi des trois KPIs (mention, citation, Share of Voice), une stratégie GEO avance à l’aveugle. Le coût d’un tracking est marginal comparé au coût d’une production qui n’aboutit jamais à une citation.
Les IA renforcent leurs propres choix : plus une source est citée, plus elle a de chances d’être recitée. Attendre douze mois laisse cet effet cumulatif jouer pour les concurrents.
FAQ
Combien de temps faut-il pour apparaître dans les réponses de ChatGPT ?
Compter 1 à 6 mois pour des résultats mesurables, selon le niveau d’autorité initial de la marque. Le mode Search peut citer un site dès qu’il est indexé par Bing, mais les citations dans les réponses génératives demandent plus de temps, le temps que l’entité de marque s’installe dans le corpus et soit confirmée par des sources tierces.
Le référencement ChatGPT remplace-t-il le SEO Google ?
Non, il le complète. Google reste le premier point d’entrée du trafic web, mais une part croissante des requêtes informationnelles passe par les IA, et un site mal positionné sur Google le sera aussi sur ChatGPT Search via l’index Bing.
Les contenus rédigés par IA sont-ils pénalisés par ChatGPT ?
Pas pénalisés au sens d’un filtre, mais clairement défavorisés à la citation. Les LLM détectent les patterns d’écriture générique et privilégient les sources avec une voix identifiable, des chiffres précis et un point de vue, ce qui rend les contenus IA non révisés peu compétitifs face à un contenu travaillé.