Le robots.txt n’est plus le petit fichier qu’on écrit une fois et qu’on oublie. Avec l’arrivée des crawlers IA, il décide à la fois de votre visibilité dans Google et de votre présence dans les réponses de ChatGPT, Claude, Gemini ou Perplexity. La bonne approche n’est pas de tout bloquer par réflexe, c’est d’arbitrer bot par bot. Voici comment configurer votre robots.txt sans saboter votre visibilité.
Pourquoi le robots.txt est redevenu un sujet stratégique
Pendant vingt ans, le robots.txt a servi à dire à Googlebot et Bingbot quelles pages ils pouvaient explorer. Le fichier était basique, on le configurait à l’installation du site, on n’y revenait jamais. Cette époque est terminée. Les IA génératives ont introduit une nouvelle catégorie de bots qui ne se comportent pas comme les moteurs de recherche classiques, et qui obligent à reprendre ce fichier en main.
Le robots.txt en 30 secondes
Le robots.txt est un simple fichier texte placé à la racine de votre site (votresite.com/robots.txt). Il contient des directives qui indiquent aux robots quelles pages ils peuvent ou non parcourir. Les commandes de base sont au nombre de quatre :
- User-agent : désigne le bot concerné par la règle qui suit
- Disallow : interdit l’accès à une URL ou un répertoire
- Allow : autorise l’accès à une URL ou un répertoire
- Sitemap : indique l’emplacement de votre plan de site
Important : le respect du robots.txt est volontaire. Les bots honnêtes le lisent et obéissent, les autres l’ignorent. Cette nuance va revenir tout au long de cet article.
Ce que les crawlers IA ont changé
Un crawler IA est un robot d’exploration qui collecte votre contenu pour l’une des deux raisons suivantes : entraîner un grand modèle de langage (LLM) ou alimenter une réponse en temps réel quand un utilisateur interroge un assistant IA. La différence avec Googlebot est structurelle. Googlebot crawle pour indexer et vous renvoyer du trafic. Un crawler IA peut aspirer votre contenu sans vous renvoyer le moindre visiteur.
L’ampleur du phénomène donne le vertige. GPTBot, le crawler d’OpenAI, génère parfois 569 millions de requêtes en un seul mois sur un réseau comme Vercel. Un propriétaire de site a rapporté 30 To de bande passante consommés par GPTBot en trente jours. Sur les grands sites web mondiaux, plus d’un tiers bloquent désormais GPTBot dans leur robots.txt. Côté usage, les chatbots IA captent une part croissante des recherches : environ 60% des internautes utilisent désormais un assistant IA pour s’informer.
Conséquence pour votre robots.txt : il ne sert plus uniquement à piloter votre SEO, il sert aussi pour votre visibilité GEO (Generative Engine Optimization). Ce sont deux décisions distinctes, parfois opposées, qui se prennent dans le même fichier.
Faites appel à une agence GEO comme WeComm pour en savoir plus.
Les crawlers IA en bref, juste ce qu’il faut pour configurer votre robots.txt
Pour bien arbitrer votre robots.txt, vous n’avez pas besoin de connaître les 25 bots du marché. Vous avez besoin de comprendre qu’il en existe deux familles au comportement radicalement différent.
Deux familles à connaître avant d’écrire votre fichier

Les bots d’entraînement parcourent le web massivement pour aspirer du contenu et l’utiliser comme matière première pour entraîner les futures versions des LLM. Quand ils passent sur votre site, ils prennent votre texte et vos images, ils alimentent un modèle qui sera ensuite vendu ou utilisé pour générer des réponses, et vous ne recevez rien en retour. Les principaux sont GPTBot (OpenAI), Google-Extended (Gemini), anthropic-ai et ClaudeBot (Anthropic), CCBot (Common Crawl, qui alimente quasiment tous les LLM open source), Meta-ExternalAgent (LLaMA), Applebot-Extended (modèles Apple) et Bytespider (ByteDance).
Les bots fetcher ne crawlent pas pour entraîner, ils crawlent à la demande, quand un utilisateur pose une question à un assistant IA. L’assistant identifie quelques pages pertinentes, les fait récupérer en temps réel, en extrait des passages et les insère dans sa réponse, souvent avec citation. Si vous bloquez ces bots, votre marque ne peut tout simplement pas apparaître dans les réponses des chatbots. Les principaux sont ChatGPT-User et OAI-SearchBot (OpenAI), Claude-Web (que beaucoup cherchent sous l’expression « claude searchbot »), PerplexityBot et Perplexity-User (Perplexity), MistralAI-User (Mistral) et DuckAssistBot (DuckDuckGo).
La règle à retenir avant toute configuration
Bloquer un bot d’entraînement protège votre propriété intellectuelle sans pénaliser votre visibilité immédiate. Bloquer un bot fetcher vous rend invisible dans les réponses générées par les LLM, instantanément et sans préavis. C’est cette distinction qui va structurer toute la suite. Si vous retenez un seul principe : ne bloquez jamais les fetcher, sauf raison très précise.
Quelle stratégie robots.txt adopter pour votre site
C’est là que la plupart des articles concurrents vous servent une réponse défensive : tout bloquer, mettre un WAF, payer une solution de gestion des bots. Cette approche convient aux grands sites éditoriaux et aux e-commerce massifs, pas forcément à votre site. Voici un arbitrage plus nuancé.
Bloquer par défaut, l’erreur classique
Le réflexe « tout bloquer pour être tranquille » est partout, parce qu’il est confortable. Le problème : il revient à se rayer volontairement de l’écosystème IA. Quand un prospect demande à ChatGPT « qui fait de la couverture sur Annecy ? » ou à Perplexity « meilleur traiteur halal à Marseille », la réponse est construite à partir des sites que les bots fetcher peuvent atteindre. Si vous les avez bloqués dans votre robots.txt, vous n’êtes pas dans la réponse. Vos concurrents qui ont laissé la porte ouverte, eux, y sont.
Cette perte est silencieuse. Vous ne la verrez pas dans Google Analytics, parce que ces visites ne s’y matérialisent pas comme un trafic SEO classique. Vous la subirez dans votre chiffre d’affaires, sans comprendre pourquoi.
Autoriser sans regarder, l’autre faute
À l’inverse, laisser tous les bots faire ce qu’ils veulent a aussi un coût. Bytespider, le crawler de ByteDance, ignore largement le robots.txt et peut générer des pics de trafic qui mettent un hébergement mutualisé à genoux. Des administrateurs systèmes ont observé l’utilisation processeur grimper à 300% sur des serveurs optimisés lors des pics de crawl IA. Ces pics peuvent ralentir le site pour les vrais visiteurs et faire baisser vos Core Web Vitals.
Au-delà de la performance, autoriser tous les bots d’entraînement, c’est accepter que votre contenu original (descriptions produits travaillées, articles de fond, fiches services) serve à entraîner des IA qui généreront ensuite des contenus quasi identiques pour vos concurrents.
La bonne approche : ouvert par défaut, fermé sélectivement
Entre les deux extrêmes, la position défendable est simple. Vous autorisez par défaut, vous bloquez uniquement trois catégories :
- Les bots agressifs qui ignorent les règles (Bytespider en tête). Vous les bloquez même si vous savez qu’ils ne respecteront pas votre robots.txt, parce que ça signale aussi votre intention juridique.
- Les bots d’entraînement si vous avez une vraie raison de protéger votre contenu (modèle économique basé sur du contenu original, descriptions produits différenciantes, articles de fond).
- Jamais les bots fetcher, sauf si vous voulez délibérément vous retirer de l’IA générative, ce qui est rarement le bon choix.
Trois profils de site et la stratégie qui correspond
Pour rendre l’approche concrète, voici comment trois profils typiques devraient configurer leur fichier.
Profil 1 : site vitrine local (artisan, commerce, salon, restaurant, prestataire de service).
Dans le GEO local, vous vendez de la confiance et de la proximité, pas du contenu original protégeable. Votre visibilité GEO Claude, LLM ChatGPT et GEO Perplexity vaut largement la bande passante consommée.
Recommandations : tout autoriser, sauf les bots agressifs (Bytespider, ImagesiftBot) que vous bloquez par principe.
Profil 2 : e-commerce (e-shop, marketplace de niche, boutique en ligne).
Vos descriptions courtes sont peut-être génériques (souvent reprises du fournisseur), mais vos contenus détaillés (guides d’usage, comparatifs, conseils experts) sont sûrement originaux. Dans le GEO e-commerce, une IA entraînée sur votre catalogue peut générer des descriptions concurrentes en quelques secondes.
Recommandations : bots fetcher autorisés (ChatGPT-User, Claude-Web, Perplexity-User, etc.), bots d’entraînement bloqués (GPTBot, Google-Extended, anthropic-ai, ClaudeBot, CCBot), bots agressifs bloqués.
Profil 3 : site de contenu (blog professionnel, formation, média, site éditorial).
Vous produisez du contenu original qui est votre actif principal. L’arbitrage est le plus serré.
Recommandations : bots fetcher autorisés (pour la visibilité et la citation), tous les bots d’entraînement bloqués, bots agressifs bloqués. C’est le profil pour lequel les enjeux de propriété intellectuelle pèsent le plus lourd dans la balance.
Configurer votre robots.txt pour les IA, étape par étape
Place à la pratique. Tous les exemples ci-dessous sont prêts à copier-coller dans votre fichier /robots.txt.
Rappel express de syntaxe
Quatre points à respecter pour que votre fichier soit interprété correctement :
- La casse compte sur les noms de user-agent. Écrivez
User-agent: GPTBotexactement comme ça, pasuser-agent: gptbot. - Une ligne vide sépare deux blocs (un bloc = un
User-agent+ ses directives). - Les commentaires commencent par
#et sont ignorés par les bots, ce qui vous permet d’annoter votre fichier pour vous souvenir de vos choix. - L’ordre n’a pas d’importance pour les blocs principaux, sauf pour le bloc
User-agent: *qui sert de règle par défaut.
Pour la référence syntaxique complète, voir la documentation officielle Google sur le robots.txt.
Bloquer un bot d’entraînement
Pattern générique
User-agent: GPTBot Disallow: /
GPTBot
User-agent: GPTBot Disallow: /
Google-Extended
User-agent: Google-Extended Disallow: /
anthropic-ai & ClaudeBot
User-agent: anthropic-ai Disallow: / User-agent: ClaudeBot Disallow: /
CCBot
User-agent: CCBot Disallow: /
Meta-ExternalAgent
User-agent: Meta-ExternalAgent Disallow: /
Bytespider & ImagesiftBot
User-agent: Bytespider Disallow: / User-agent: ImagesiftBot Disallow: /
Autoriser explicitement les fetcher
C’est l’étape que tout le monde oublie. Si votre robots.txt commence par un bloc User-agent: * Disallow: / (ce qui arrive plus souvent qu’on ne le pense, notamment sur des installations WordPress mal configurées), vous bloquez aussi les bots fetcher. La solution : déclarer explicitement les bots que vous voulez laisser passer.
Fetcher IA à autoriser
User-agent: ChatGPT-User Allow: / User-agent: OAI-SearchBot Allow: / User-agent: Claude-Web Allow: / User-agent: PerplexityBot Allow: / User-agent: Perplexity-User Allow: / User-agent: MistralAI-User Allow: / User-agent: DuckAssistBot Allow: /
Le robots.txt visibilité GEO prêt à copier
Voici un fichier complet, commenté, qui matérialise la stratégie « ouvert par défaut, fermé sélectivement ». Adaptez-le à votre profil en décommentant les sections qui vous concernent.
robots.txt visibilité GEO
# robots.txt - Configuration orientée visibilité GEO # Approche : ouvert par défaut, fermé sélectivement # ==================================== # Bots agressifs (à bloquer dans tous les cas) # ==================================== User-agent: Bytespider Disallow: / User-agent: ImagesiftBot Disallow: / # ==================================== # Bots d'entraînement IA # À DÉCOMMENTER si vous voulez protéger votre contenu original # Aucun impact sur votre SEO ni sur votre présence dans les chatbots IA # Recommandé pour e-commerce et sites de contenu # ==================================== # User-agent: GPTBot # Disallow: / # User-agent: Google-Extended # Disallow: / # User-agent: anthropic-ai # Disallow: / # User-agent: ClaudeBot # Disallow: / # User-agent: CCBot # Disallow: / # User-agent: Meta-ExternalAgent # Disallow: / # User-agent: Applebot-Extended # Disallow: / # ==================================== # Fetcher IA (à laisser passer pour rester citable) # ==================================== User-agent: ChatGPT-User Allow: / User-agent: OAI-SearchBot Allow: / User-agent: Claude-Web Allow: / User-agent: PerplexityBot Allow: / User-agent: Perplexity-User Allow: / User-agent: MistralAI-User Allow: / User-agent: DuckAssistBot Allow: / # ==================================== # Règle par défaut pour les autres bots # ==================================== User-agent: * Allow: / Disallow: /wp-admin/ Disallow: /admin/ Disallow: /panier/ Disallow: /commande/ Disallow: /mon-compte/ # ==================================== # Sitemap # ==================================== Sitemap: https://votresite.com/sitemap.xml
Copiez ce fichier, remplacez l’URL du sitemap par celle de votre site, et décommentez les sections qui correspondent à votre profil.
Cas particulier selon votre CMS
Votre CMS génère probablement déjà un robots.txt par défaut, et vous pouvez soit le remplacer, soit l’éditer via un plugin.
- WordPress : le fichier par défaut est généré dynamiquement, vous ne le verrez pas par FTP. Utilisez un plugin SEO (Rank Math, Yoast SEO, SEOPress) qui vous permet d’écrire un robots.txt personnalisé depuis l’interface d’administration. Vérifiez après publication en accédant à votresite.com/robots.txt dans votre navigateur.
- Shopify : éditez le fichier robots.txt.liquid directement dans le thème (Boutique en ligne > Thèmes > Modifier le code). Vous y ajoutez vos blocs de directives sans toucher au reste généré par Shopify.
- PrestaShop : générez un robots.txt depuis l’admin (Trafic > SEO et URL > robots.txt). Pour les directives IA spécifiques, éditez ensuite le fichier directement par FTP.
- Webflow : champ dédié dans les paramètres du site (Site Settings > SEO > Indexing > robots.txt).
- Wix : disponible via l’éditeur SEO avancé, dans les paramètres SEO du site.
- Squarespace : champ « robots.txt personnalisé » dans Settings > Advanced > SEO.
- Drupal, Joomla, autres CMS classiques : le robots.txt se trouve à la racine du site, éditable directement par FTP ou via le gestionnaire de fichiers de votre hébergeur.
Si votre plateforme ne propose ni édition directe ni champ personnalisé, c’est un signal que vous avez atteint une limite à laquelle elle n’a pas de réponse.
Maintenir et tester votre robots.txt
Un robots.txt qu’on configure une fois et qui n’est jamais audité ne sert qu’à moitié. Les bots changent, les LLM évoluent, et un fichier obsolète peut soit vous rendre invisible, soit laisser passer des bots dont vous ne voulez plus.
Vérifier que tes directives sont respectées
Les logs de votre serveur sont la seule source fiable pour savoir qui crawle votre site. Sur un hébergement mutualisé classique, ils sont accessibles via le panneau de contrôle (cPanel, Plesk). Sur un VPS ou un dédié, ils se trouvent généralement dans /var/log/apache2/ ou /var/log/nginx/.
Cherchez les user-agents que vous voulez surveiller (GPTBot, ClaudeBot, Bytespider, etc.) et observez :
- Les codes HTTP renvoyés. Un bot qui reçoit du 200 passe, un bot qui reçoit du 403 ou du 404 est bloqué.
- La fréquence des passages. Un bot qui frappe 500 fois par heure pose problème.
- L’adresse IP du bot. Les éditeurs (OpenAI, Anthropic, Google, Perplexity) publient les plages IP officielles de leurs crawlers. Un user-agent « GPTBot » qui vient d’une IP hors de la plage officielle est probablement un imposteur.
Pour suivre l’activité des principaux crawlers IA à l’échelle du web, Cloudflare Radar publiez régulièrement des statistiques actualisées qui vous donnent une bonne vue d’ensemble.
Mettre à jour votre fichier régulièrement
La liste des crawlers IA évolue vite. De nouveaux bots apparaissent chaque trimestre, certains anciens sont retirés (anthropic-ai a été remplacé par ClaudeBot, par exemple), d’autres changent de comportement. Prévoyez deux audits par an minimum de votre robots.txt :
- Vérifier que les directives existantes pointent bien sur les noms de bots actuels
- Ajouter les nouveaux bots que vous souhaitez bloquer ou autoriser
- Revoir votre arbitrage à la lumière de l’évolution de votre activité
Pour vérifier la liste à jour des bots OpenAI, consultez la documentation officielle d’OpenAI sur ses crawlers.
Quand le robots.txt ne suffit plus
Soyons clairs : pour les bots qui s’en moquent (Bytespider en première ligne, scrapers déguisés en second), aucune directive ne les arrêtera. Si vous observez des pics réguliers liés à ce type de trafic, il faut passer à des moyens de défense actifs. Trois leviers, par ordre de complexité :
- Blocage IP via
.htaccessounginx.conf: vous refusez les requêtes provenant de plages IP identifiées comme malveillantes. Efficace mais fastidieux à maintenir. - Rate limiting via ModSecurity (Apache) ou les modules dédiés Nginx : vous limitez le nombre de requêtes par minute autorisé pour un même user-agent, ce qui ralentit les bots agressifs sans les bloquer complètement.
- Solutions managées comme Cloudflare AI Crawl Control ou DataDome : vous délèguez la détection et le blocage à une plateforme spécialisée. C’est l’option pour ceux qui n’ont pas de ressources techniques internes et qui veulent dormir tranquilles.
5 erreurs robots.txt à éviter face aux IA
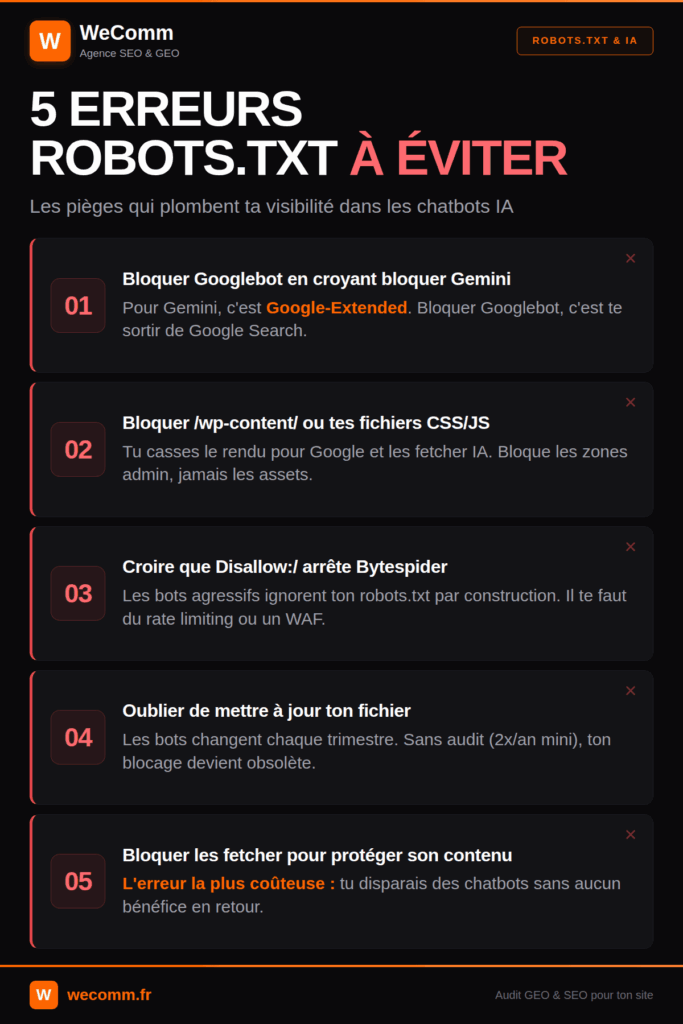
Une checklist rapide des pièges les plus fréquents repérés en audit.
- Bloquer Googlebot en croyant bloquer Gemini. Googlebot indexe votre site pour Google Search, Google-Extended alimente l’entraînement de Gemini. Pour bloquer Gemini sans casser votre SEO, c’est
User-agent: Google-Extendedqu’il vous faut, jamaisUser-agent: Googlebot. - Bloquer
/wp-content/ou tes fichiers CSS/JS. Une directiveDisallow: /wp-content/casse le rendu de vos pages pour Google et pour les fetcher IA, qui ne voient plus qu’un site cassé. Laissez/wp-content/accessible et bloquez uniquement les zones admin et privées. - Croire que
Disallow: /suffit à arrêter Bytespider et compagnie. Les bots agressifs ignorent votre robots.txt par construction. La directive sert à signaler votre intention, mais elle n’arrête rien techniquement. Si vous observez des pics, il faut passer aux leviers actifs (rate limiting, WAF). - Oublier de mettre à jour votre fichier. Le bot que vous avez bloqué l’an dernier a peut-être été retiré, et son remplaçant passe librement parce que vous n’avez jamais ajouté son user-agent.
- Bloquer les fetcher en pensant protéger son contenu. L’erreur la plus coûteuse. Un
Disallow: /sur ChatGPT-User, Claude-Web ou Perplexity-User vous raye de l’écosystème IA générative sans aucun bénéfice en retour, puisque votre contenu reste accessible aux bots d’entraînement et aux scrapers déguisés.
FAQ
Faut-il bloquer ChatGPT dans son robots.txt ?
Tout dépend du bot. GPTBot collecte pour l’entraînement, vous pouvez le bloquer sans perdre votre présence dans l’assistant. ChatGPT-User et OAI-SearchBot récupèrent votre page quand un utilisateur pose une question.
Comment savoir si un bot IA crawle mon site ?
Analysez vos logs serveur en filtrant sur les user-agents connus (GPTBot, ClaudeBot, PerplexityBot, etc.) et croisez les IP avec les plages officielles publiées par les éditeurs. Un outil de monitoring spécialisé GEO comme WeGEO automatise ce suivi.
Quelle différence entre Googlebot et Google-Extended ?
Googlebot crawle pour Google Search et conditionne votre SEO. Google-Extended ne sert qu’à l’entraînement de Gemini. Vous pouvez bloquer Google-Extended sans aucun impact sur votre positionnement Google.
Mon robots.txt doit-il être différent selon mon hébergement ?
La syntaxe ne change pas, les mesures complémentaires oui. Un mutualisé est plus vulnérable aux pics de crawl IA, et passer à un VPS ou à une solution managée devient vite rentable face à un trafic agressif récurrent.
En résumé
Le robots.txt n’est ni un mur ni une porte grande ouverte, c’est un point de contrôle où vous décidez bot par bot qui mérite l’accès à votre contenu. La règle par défaut est l’ouverture, parce que votre visibilité dans ChatGPT, Claude, Gemini et Perplexity est devenue un canal d’acquisition aussi sérieux que Google Search lui-même. Vous fermez sélectivement : les bots agressifs qui ignorent les règles (Bytespider d’office), les bots d’entraînement si vous avez du contenu original à protéger, jamais les fetcher.
Configurez votre fichier avec le modèle fourni dans cet article, vérifiez qu’il fonctionne en regardant vos logs, mettez-le à jour deux fois par an. C’est le minimum vital pour piloter votre visibilité dans l’écosystème IA.
Si vous voulez aller plus loin et savoir exactement quels bots IA passent sur votre site, à quelle fréquence et avec quel impact sur votre présence dans les réponses des LLM, un audit GEO WeComm vous donne l’état des lieux. Et pour un suivi en continu, WeGEO monitore en temps réel votre visibilité dans les chatbots IA et l’activité des crawlers sur vos pages.