Schema.org pour le GEO n’est plus une option technique, mais le minimum vital pour exister face aux moteurs d’IA générative. Sans balisage en données structurées correctement implémenté, vos pages restent illisibles pour ChatGPT, Perplexity ou Gemini, qui privilégient des sources qu’ils comprennent sans ambiguïté. Vous balisez déjà votre site mais aucune IA ne vous cite ?
Qu’est-ce que Schema.org ?
Schema.org est un vocabulaire standardisé de balisage qui décrit le contenu d’une page web dans un langage structuré que les moteurs de recherche et les IA génératives peuvent interpréter sans ambiguïté. Concrètement, c’est une bibliothèque partagée de « types » (Article, Person, LocalBusiness, Product, FAQPage…) et de « propriétés » (author, address, price, openingHours…) qui permettent d’étiqueter une information pour qu’une machine comprenne ce qu’elle représente.
Google, Microsoft, Yahoo et Yandex lancent ce vocabulaire en juin 2011 pour uniformiser la lecture des pages web par les moteurs. Il compte aujourd’hui plus de 800 types, sous la gouvernance d’un W3C Community Group ouvert.
Vocabulaire ou format : la confusion fréquente
Schema.org définit le vocabulaire. Le format d’écriture, lui, change selon trois options :
- JSON-LD : bloc JSON dans une balise <script type= »application/ld+json »>, séparé du contenu visible
- Microdata : attributs HTML (itemscope, itemtype, itemprop) intégrés au markup
- RDFa : attributs HTML enrichis (vocab, typeof, property)

Pourquoi Schema.org est devenu critique pour le GEO
Le balisage Schema servait, dans l’ère SEO classique, à obtenir des rich snippets : étoiles de notation, prix dans la SERP, accordéon FAQ, fil d’Ariane. Un confort de visibilité, rarement un facteur de classement direct. Cette époque est révolue. Le référencement des moteurs d’IA générative ont changé les règles du jeu : Schema.org n’est plus un bonus, c’est leur source de vérité.
L’infrastructure invisible des réponses IA
ChatGPT, Perplexity, Gemini, Claude ou les AI Overviews de Google partagent un fonctionnement commun : ils ingèrent du contenu web, le synthétisent et le citent. Pour trier la masse, ils privilégient les pages où l’information se présente déjà structurée. Une fiche LocalBusiness bien balisée fournit au modèle votre nom officiel, votre adresse, vos horaires, votre zone d’intervention et votre note moyenne dans un format unique et non ambigu. À l’inverse, une page non balisée force le LLM à deviner, et il préférera presque toujours un concurrent qui ne lui impose pas ce calcul.
De « indexé par Google » à « cité par les IA »
L’enjeu a basculé. Hier, l’objectif était la position 1 sur une requête. Aujourd’hui, c’est de figurer dans les sources citées d’une réponse générée. Les deux mondes coexistent encore, mais leurs leviers convergent : structurer son contenu en données machine-readable devient la couche commune. Schema.org est ce qui permet à votre site d’exister à la fois pour Google, pour Bing, pour ChatGPT et pour Perplexity, sans dupliquer l’effort.
SEO traditionnel et GEO : ce qui change pour les données structurées
Les deux disciplines, référencement naturel et Generative Engine Optimization, utilisent le même vocabulaire Schema.org, mais avec des priorités, des lecteurs et des indicateurs différents. Comprendre ces écarts évite de baliser son site avec les réflexes SEO classiques alors que les enjeux GEO en demandent d’autres.
| Critère | SEO traditionnel | GEO |
| Objectif | Rich snippet, position 1 sur SERP | Citation dans la réponse IA générée |
| Lecteur cible | Crawler Googlebot, Bingbot | LLM (ChatGPT, Perplexity, Gemini, Claude, Copilot) |
| Schémas prioritaires | Article, Product, Review, BreadcrumbList | Organization, FAQPage, HowTo, Person, ClaimReview |
| Propriété critique | aggregateRating, price, image | sameAs, mentions, about, knowsAbout |
| Format dominant | JSON-LD ou Microdata | JSON-LD quasi exclusif |
| Validation | Rich Results Test, Search Console | Tests prompts manuels + monitoring de citations |
| Indicateur de succès | CTR, position moyenne, impressions enrichies | Taux de citation, présence dans AI Overviews, trafic IA |
Comment les LLMs parsent et utilisent Schema.org
Les modèles d’IA génératives lisent Schema.org de deux manières. À l’entraînement, ils ingèrent des dumps web (Common Crawl, datasets ouverts) dont ils extraient le JSON-LD pour nourrir leur knowledge graph interne. En temps réel, leurs modules de recherche (RAG, Retrieval-Augmented Generation) crawlent le web pour répondre à une requête, et privilégient les pages déjà structurées. Un site bien balisé existe dans la mémoire longue du modèle et dans ses récupérations contextuelles.
Schema comme ancre d’entité
Le rôle le plus puissant de Schema.org pour les LLMs n’est pas de décrire un contenu, c’est de désambiguïser une entité. Sans ancrage, « WeComm » peut désigner une agence, un produit logiciel ou rien du tout. Avec un balisage Organization + sameAs vers Wikidata, LinkedIn et Google Business Profile, le modèle relie tous ces signaux à une fiche d’identité unique. C’est la différence entre être cité comme « une agence » et être cité comme « WeComm, agence SEO et GEO française ».
Ce que Schema ne résout PAS
Un excellent balisage sur un contenu médiocre ne génère aucune citation IA. Schema.org reste un amplificateur, pas un substitut. Les LLMs vérifient la cohérence entre contenu visible et balisage, et pénalisent en silence les pages où le JSON-LD ment. La qualité éditoriale optimisant les contenus pour les moteurs IA, l’autorité du domaine et la fraîcheur de l’information restent les facteurs décisifs.
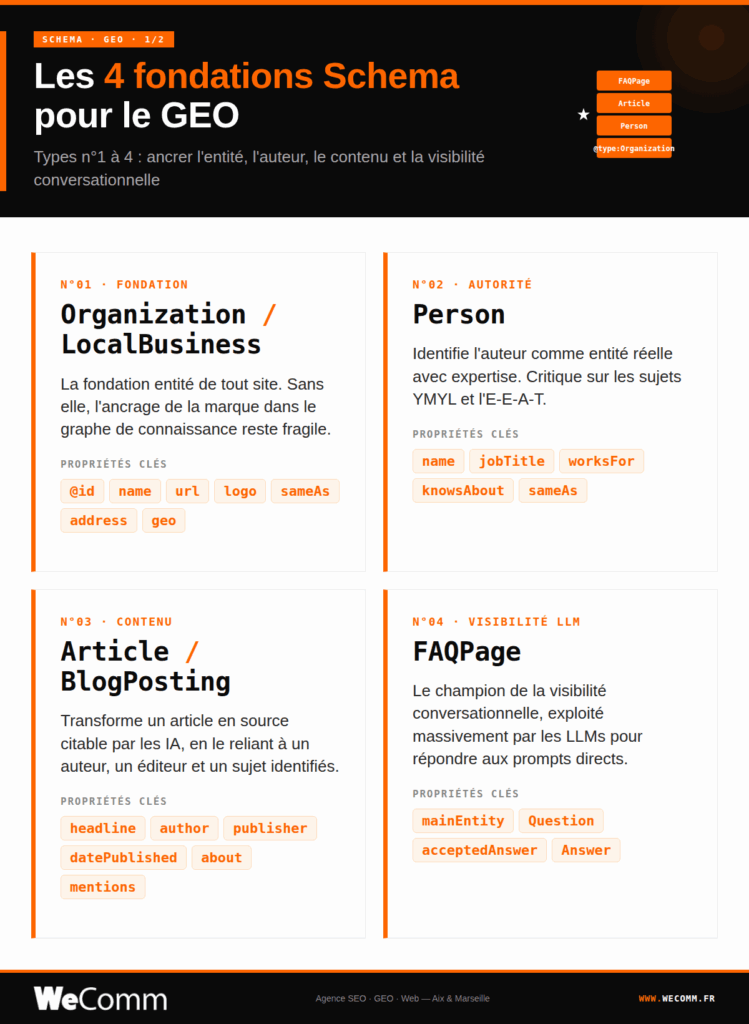
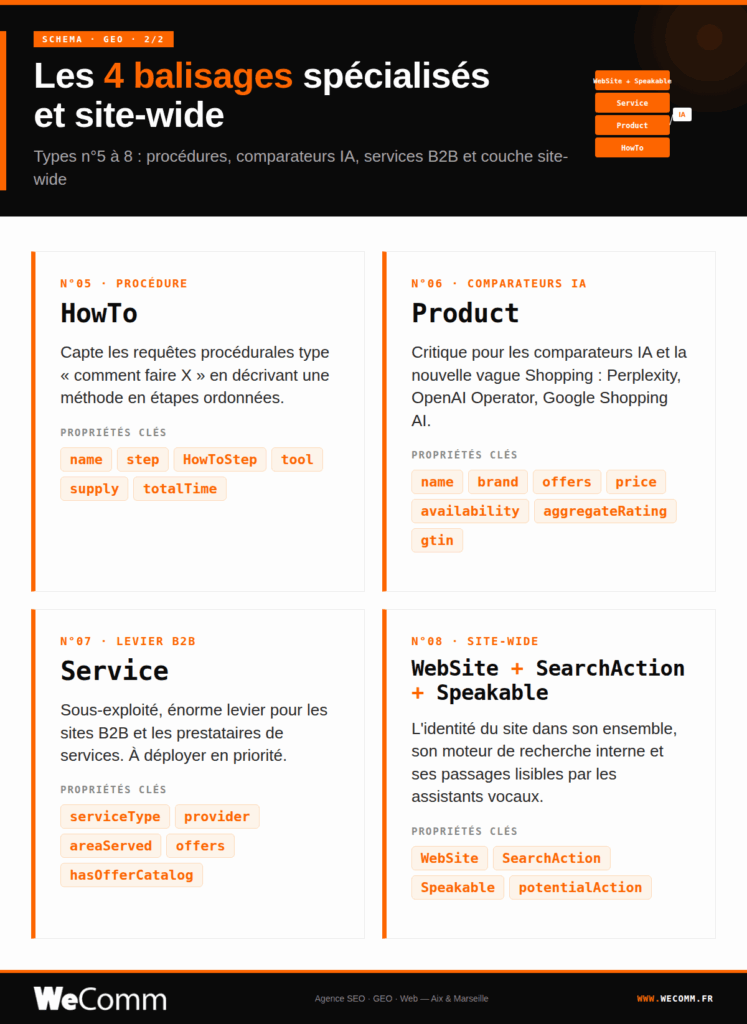
Les 8 types Schema prioritaires pour le GEO
Tous les types Schema.org ne se valent pas pour la visibilité IA. Voici les huit balisages qui pèsent réellement sur les citations LLM, du plus fondamental au plus avancé.
- Organization / LocalBusiness : la fondation entité de tout site. Propriétés clés : @id, name, url, logo, sameAs (Wikidata, LinkedIn, Google Business Profile), plus address, geo, openingHours, areaServed pour un LocalBusiness. Erreur fréquente : un sameAs limité aux réseaux sociaux qui laisse l’ancre d’entité fragile.
- Person : identification de l’auteur comme entité réelle avec expertise, critique pour les sujets YMYL et l’E-E-A-T pour le GEO. Propriétés clés : name, jobTitle, worksFor, knowsAbout, sameAs. Erreur fréquente : un Person sans worksFor ni sameAs, l’auteur reste alors une chaîne de caractères, pas une entité reconnue.
- Article / BlogPosting : le balisage qui transforme un article en source citable par une IA, en le reliant à un auteur, un éditeur et un sujet identifié. Propriétés clés : headline, author, publisher, datePublished, dateModified, about, mentions. Erreur fréquente : omettre about et mentions que les LLMs utilisent pour catégoriser le sujet.
- FAQPage : champion de la visibilité conversationnelle, exploité massivement par les LLMs pour répondre aux prompts directs. Propriétés clés : mainEntity (liste de Question avec acceptedAnswer typé Answer). Erreur fréquente : baliser une FAQPage qui n’existe pas dans le DOM visible, ou afficher 8 questions à l’écran mais en baliser 20.
- HowTo : capte les requêtes procédurales du type « comment faire X » en décrivant une méthode en étapes ordonnées. Propriétés clés : name, step (avec HowToStep numérotés), tool, supply, totalTime. Erreur fréquente : utiliser HowTo pour un article descriptif sans étapes réelles, Google a durci sa documentation sur ce point.
- Product : critique pour les comparateurs IA et la nouvelle génération de Shopping (Perplexity Shopping, OpenAI Operator, Google Shopping AI). Propriétés clés : name, brand, offers (avec price, priceCurrency, availability), aggregateRating, review, gtin ou sku. Erreur fréquente : offers sans priceCurrency ou availability, ce qui rend le balisage invalide pour les comparateurs.
- Service : sous-exploité, énorme levier pour les sites B2B et les prestataires. Propriétés clés : serviceType, provider (lié à votre Organization), areaServed, offers, hasOfferCatalog. Erreur fréquente : confondre Service et Product, un audit SEO est un Service, pas un Product.
- WebSite + SearchAction + Speakable : la couche site-wide à ne pas oublier. WebSite identifie votre site dans son ensemble, SearchAction déclare votre moteur de recherche interne, Speakable désigne les passages lisibles par les assistants vocaux. Erreur fréquente : oublier ces balisages au profit des seuls Schemas page-level, ce qui prive le site d’une fiche d’identité globale.
Implémentation technique : JSON-LD, où et comment
Placement du balisage
Le JSON-LD se place idéalement dans le <head> de la page, dans une balise <script type= »application/ld+json »>. Le placer dans le <body> reste accepté mais expose à des troncatures de crawl. Une page peut contenir plusieurs blocs distincts (Organization, BlogPosting, FAQPage), mais l’approche graphe unique reste plus propre.
Stratégie graphe vs blocs distribués
Deux écoles. Multiplier les blocs JSON-LD un par entité : simple, mais sans lien explicite entre eux. Regrouper tout dans un seul bloc avec une propriété @graph où chaque entité possède un @id et se référence mutuellement : plus complexe à structurer, mais les LLMs lisent ce format beaucoup plus efficacement car il leur livre l’arbre des relations directement.
Implémentation selon votre stack
- WordPress : RankMath et Yoast SEO Premium couvrent les types courants. Pour Organization, Person ou Service complets, prévoir un plugin dédié (Schema Pro, WPSSO) ou de l’ACF + injection manuelle dans le <head>.
- HubSpot : module HubL custom dans le template, avec balises conditionnelles selon le type de page.
- Webflow : balise embed dans le head ou le body, avec interpolation des champs CMS.
- Shopify : sections theme.liquid pour le site-wide, templates produit/collection pour les Product spécifiques.
- Sites custom : génération côté serveur, avec fallback SSR obligatoire si rendu JavaScript.
L’erreur du balisage qui ment
Le piège le plus courant : déclarer dans le JSON-LD ce qui n’apparaît pas dans le DOM visible. FAQ avec 20 questions balisées mais 8 affichées, avis fictifs dans aggregateRating, prix dans offers qui diffère de celui affiché. Google et les LLMs croisent systématiquement balisage et contenu visible. La sanction n’est pas une pénalité manuelle, c’est l’invisibilisation progressive : disparition des AI Overviews et des citations, sans alerte.
Stratégie de priorisation : par où commencer selon votre type de site
Implémenter les huit types Schema d’un coup n’a pas de sens : trop coûteux, trop dilué. La logique gagnante consiste à identifier les types qui apportent le plus de valeur à votre profil de site, et à itérer.
| Type de site | Priorité 1 | Priorité 2 | À ajouter ensuite |
| Vitrine PME locale | LocalBusiness | FAQPage | Service, Review |
| Blog éditorial / média | Article + Person | Organization | FAQPage, BreadcrumbList |
| E-commerce | Product + Offer | Organization | AggregateRating, Review, BreadcrumbList |
| SaaS B2B | SoftwareApplication | Service + Organization | FAQPage, Person (auteurs) |
| Agence / cabinet | ProfessionalService | Person | Article, FAQPage, Review |
Méthode d’itération
Trois règles pour ne pas se perdre. Un, démarrer par Organization (ou LocalBusiness) au niveau site-wide : c’est l’ancre dont dépend la lecture de tout le reste. Deux, ajouter ensuite le type qui correspond à la page la plus rentable (le top template par trafic ou par CA). Trois, mesurer avant d’élargir : un Schema bien fait sur 20% des pages bat un Schema bâclé sur 100%.
7 erreurs courantes à éviter
Aucune des erreurs qui suivent ne déclenche une pénalité visible. Elles produisent une invisibilisation silencieuse : votre site reste indexé, mais les IA cessent de le citer sans qu’aucun outil ne l’indique. Voici les sept que l’on retrouve le plus souvent en audit GEO.
- Balisage qui ne reflète pas le contenu visible. Afficher une chose à l’écran et en déclarer une autre dans le JSON-LD. Google et les LLMs croisent les deux et sanctionnent la divergence par l’invisibilisation, sans alerte.
- Schémas en doublon ou contradictoires. Un BlogPosting balisé deux fois avec des dates différentes, une Organization déclarée trois fois avec des noms variants. Les moteurs choisissent au hasard ou ignorent tout le bloc.
- Absence de @id pour relier les entités. Sans identifiants explicites, l’Article ne se rattache pas à son auteur, l’auteur ne se rattache pas à l’Organization, et le graphe ne se forme jamais.
- sameAs absent ou limité aux réseaux sociaux. Sans lien vers Wikidata, Google Business Profile ou LinkedIn d’entreprise, votre Organization reste une chaîne de caractères dans le graphe des LLMs.
- Schema Organization absent ou minimal. Une Organization sans logo, sans sameAs, sans contactPoint reste techniquement valide mais éditorialement vide. Les IA la traitent comme une coquille.
- FAQPage qui ment au DOM. Baliser 20 questions alors que la page en affiche 8, ou inversement, déclenche un déclassement silencieux. Le balisage doit refléter exactement les questions visibles.
- Imbrication trop profonde. Une structure JSON-LD imbriquée sur quatre ou cinq niveaux casse le parsing de certains crawlers et LLMs. Privilégier le format @graph avec entités à plat reliées par @id.

Mesurer l’impact sur le GEO
Côté SEO, Search Console affiche les impressions enrichies, le CTR et les erreurs de validation : la mesure est simple. Côté GEO, aucune plateforme officielle n’indique si ChatGPT, Perplexity ou Gemini citent votre site, ni avec quelle fréquence. Il faut composer.
KPI à suivre
- SEO : impressions de rich results, CTR par type de balisage (Search Console > Apparence dans la recherche)
- GEO : taux de citation par moteur IA, nombre d’occurrences en AI Overviews, trafic référent depuis chatgpt.com, perplexity.ai, gemini.google.com
- Entité : présence de votre marque dans le knowledge panel de Google, fiche Wikidata active, rattachement correct dans les « à propos de » des LLMs
Outils de monitoring
Plusieurs solutions, comme les outils GEO, ont émergé pour suivre les citations IA : Profound et Otterly pour les agences grand compte, WeGEO pour les agences SEO françaises souhaitant un suivi mutualisé client par client. Aucun outil n’offre encore la profondeur d’un Search Console, mais l’industrie progresse vite.
Méthode A/B simple
Sélectionnez deux groupes de pages comparables (même typologie, même trafic moyen, mêmes auteurs). Renforcez le Schema sur un seul groupe, mesurez sur 60 à 90 jours l’évolution du trafic référent IA, des citations détectées et des impressions enrichies. La différence devient lisible à partir de 6 à 8 semaines sur la plupart des sites.
Conclusion : Schema.org, votre passeport pour les IA
Schema.org a changé de statut. Hier accessoire SEO orienté rich snippets, aujourd’hui prérequis non négociable pour exister face aux moteurs d’IA générative. Sans balisage cohérent, votre site reste lisible par Google mais devient muet pour ChatGPT, Perplexity ou Gemini.
Trois priorités à retenir : ancrer votre entité avec un Organization solide et un sameAs étoffé, structurer vos contenus stratégiques (Article, FAQPage, Product, Service selon votre stack), et mesurer l’impact réel sans se contenter du Rich Results Test. Le balisage n’amplifie que ce qui existe déjà : sans contenu de qualité ni autorité de domaine par le netlinking pour GEO par exemple, aucun Schema ne fera de miracle.
L’enjeu n’est plus d’apparaître dans une SERP, mais d’être cité dans une réponse. Schema.org est ce qui rend cette citation possible.
FAQ
Le balisage Schema améliore-t-il directement le classement Google ?
Non, Schema.org n’est pas un facteur de classement direct dans l’algorithme Google. Il améliore en revanche la compréhension du contenu par les moteurs, ce qui débloque l’éligibilité aux rich results, aux AI Overviews et aux citations LLM, des leviers qui finissent par influencer le trafic réel.
Comment vérifier que mon balisage Schema fonctionne ?
Utilisez le Rich Results Test de Google et le Schema Markup Validator pour valider syntaxe et éligibilité. Pour l’impact GEO, complétez avec des tests prompts manuels sur ChatGPT, Perplexity et Gemini, et un outil de monitoring de citations comme Profound, Otterly ou WeGEO.
Comment ajouter Schema.org sur WordPress sans plugin ?
Injectez votre JSON-LD directement dans le <head> via le fichier functions.php du thème, en accrochant une fonction au hook wp_head. Cette approche offre un contrôle total et évite la dépendance à un plugin tiers, mais demande une maintenance manuelle à chaque évolution du site ou du vocabulaire Schema.org.