Pour être cité comme source par l’IA Perplexity, il faut publier du contenu frais (82% des citations vont à des pages mises à jour dans les trente derniers jours), répondre directement à la question dans les premières lignes du texte, structurer l’information pour l’extraction par l’IA (Schema.org, listes, tableaux), et bâtir une présence sur des sources tierces (Reddit, Wikipedia, médias) qui pèsent pour 85% des mentions de marque dans les réponses générées. Voici la méthode complète de référencement pour Perplexity.
Pourquoi viser une citation par l’IA de Perplexity
Perplexity est un moteur de réponses lancé en 2022 par d’anciens ingénieurs de Google, DeepMind et OpenAI. Avec 780 millions de requêtes mensuelles et 22 millions d’utilisateurs actifs, il s’impose comme l’alternative crédible à Google pour les recherches qui exigent une information vérifiable et synthétique.
Sa singularité tient à la transparence. Là où ChatGPT paraphrase souvent sans attribution, Perplexity affiche systématiquement les liens cliquables vers ses sources. Cette caractéristique en fait le moteur IA préféré des professions à forte exigence de fiabilité : journalistes, médecins, juristes, analystes, décideurs B2B. Concrètement, une citation par le référencement de Perplexity génère donc un trafic ultra-qualifié.
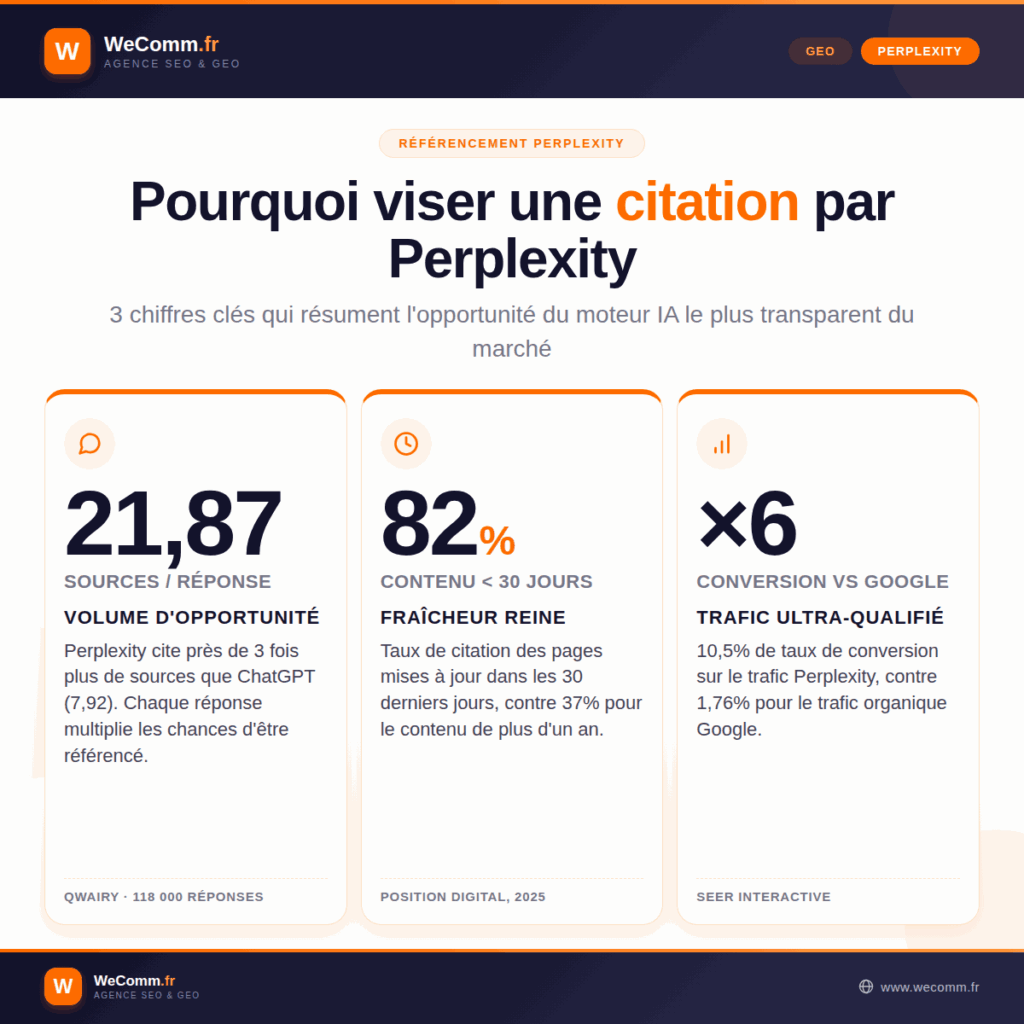
Trois chiffres permettent de saisir l’ampleur de l’opportunité.
D’abord, Perplexity cite 21,87 sources par réponse en moyenne, soit près de trois fois plus que le LLM ChatGPT (7,92), selon l’analyse Qwairy menée sur 118 000 réponses au troisième trimestre 2025. Chaque réponse est donc une opportunité multiple de figurer dans les sources.
Ensuite, le trafic référent provenant de Perplexity convertit à 10,5%, contre 1,76% pour le trafic organique Google, d’après les données Seer Interactive. Un visiteur Perplexity vaut donc, à volume égal, près de six fois un visiteur Google.
Enfin, Perplexity affiche le taux d’erreur de citation le plus bas du marché : 37%, contre 67% pour ChatGPT Search, dans le test mené sur 200 requêtes par le Tow Center for Digital Journalism de l’université Columbia en mars 2025. C’est précisément cette fiabilité qui justifie l’attention que les utilisateurs portent aux sources affichées.
Comment Perplexity IA choisit ses sources

Avant d’aborder les leviers, il faut comprendre comment l’algorithme décide d’afficher tel domaine plutôt qu’un autre. La sélection s’appuie sur quatre critères pondérés, identifiés par croisement de plusieurs études récentes.
| Critère de sélection | Donnée chiffrée | Source |
| Fraîcheur du contenu | 82% de taux de citation pour le contenu de moins de 30 jours, 37% au-delà d’un an | Position Digital, 2025 |
| Présence multi-plateformes | 85% des mentions de marque viennent de pages tierces | AirOps, State of AI Search 2026 |
| Structure d’extraction | Listicles : 21,9% des citations, articles classiques : 16,7%, fiches produits : 13,7% | Étude Wix, 2026 |
| Vérifiabilité factuelle | Taux d’erreur de citation le plus bas (37% contre 67% pour ChatGPT Search) | Tow Center, Columbia University, mars 2025 |
La fraîcheur est le critère le plus discriminant. Un contenu obsolète, même de qualité, sera écarté au profit d’une source plus récente. Le référencement de Perplexity est mis à jour, via son index, en continu et un nouveau contenu peut apparaître dans les citations sous 24 à 72 heures.
L’autorité topique se construit sur l’ensemble de votre écosystème de mentions, pas uniquement sur votre site. Les marques sont 6,5 fois plus citées via des sources tierces que via leur propre domaine, ce qui change radicalement la logique de visibilité par rapport au SEO classique.
La structure est ce qui sépare un contenu lisible par un humain d’un contenu extractible par une IA. Perplexity favorise tout ce qu’elle peut découper proprement : listes, tableaux, FAQ, paragraphes courts denses en information.
La vérifiabilité enfin est le critère propre à l’ADN de Perplexity. L’algorithme croise plusieurs sources avant de générer une réponse, et privilégie les contenus chiffrés, datés, sourcés. Une affirmation invérifiable vaut zéro citation.
Les leviers pour être cité comme source par Perplexity
Les six pratiques qui suivent transforment ces critères de sélection en actions concrètes. Elles sont classées par impact estimé sur le taux de citation.
Répondre à la question dès les premières lignes
Les analyses de citations menées sur les LLM montrent que 44,2% des extraits cités proviennent des trente premiers pourcents du texte, soit l’introduction et le tout début du corps de l’article. Tout ce qui arrive après est massivement moins repris.
La méthode dite de la pyramide inversée résout ce problème : on répond à la question dans le premier paragraphe (40 à 60 mots), puis on développe les nuances, exemples et démonstrations dans la suite. C’est l’inverse de la rhétorique classique qui construit l’argumentation avant la conclusion.
Concrètement, sur un article ciblant la question « Comment optimiser son site pour Perplexity ? », la réponse synthétique doit figurer dans les six premières lignes, avec les mots-clés et les chiffres marqueurs. Les détails viennent après. Ce papier-ci applique cette logique, vous en avez la démonstration en intro.
Actualiser le contenu chaque mois, pas chaque année
L’écart entre 82% de citations pour le contenu frais et 37% pour le contenu ancien est trop important pour laisser des articles dormir. La routine éditoriale doit prévoir une mise à jour mensuelle des articles piliers, et trimestrielle des articles secondaires.
Trois actions techniques renforcent ce signal de fraîcheur :
- Mettre à jour les champs datePublished et dateModified dans le balisage Schema, et pas seulement la date affichée à l’écran.
- Afficher une mention visible « dernière mise à jour » en haut de l’article.
- Intégrer l’année en cours dans le H1, le H2 principal et l’introduction, ce qui augmente le taux de citation Perplexity d’environ 30% selon les tests menés par BlogPros.
Attention, une simple bascule de date sans modification du contenu n’a pas d’effet durable. L’algorithme détecte les refresh cosmétiques. La mise à jour doit apporter une vraie valeur : statistique récente, nouveau paragraphe, suppression d’une information périmée, exemple récent.
Construire une présence sur les sources tierces que l’IA Perplexity privilégie
C’est le levier le plus sous-estimé en France. Les 85% de mentions de marque provenant de pages tierces sont concentrés sur quelques plateformes. Reddit a longtemps représenté jusqu’à 46,7% des citations Perplexity selon l’analyse initiale de Bluefish, un chiffre redescendu autour de 24% au premier trimestre 2026 d’après le rapport Tinuiti, à mesure que la plateforme diversifie ses sources. Reddit reste néanmoins, et de loin, la plateforme communautaire la plus citée.
Les quatre actions à prioriser :
- Une présence Reddit authentique sur les subreddits métier. Pas de promo, pas de message commercial, mais des réponses détaillées et utiles signées avec un compte humain identifiable. Les commentaires de plus de 300 mots avec sources et structure sont cités plus de trois fois plus souvent que les réponses courtes.
- Une page Wikipedia bien sourcée si la marque est éligible aux critères d’admissibilité. Wikipedia est dans le top 3 des sources Perplexity et alimente une part importante des entraînements LLM.
- Des mentions presse et médias spécialisés dans la thématique. Une mention dans un média sectoriel pèse davantage qu’un backlink technique pour le GEO. Les mentions sans lien fonctionnent presque aussi bien que les liens.
- Des profils complets sur les annuaires de niche (G2, Capterra, Trustpilot pour le B2B, ou les équivalents métier dans chaque secteur).
Structurer le contenu pour faciliter l’extraction par l’IA
L’IA ne lit pas vos articles comme un humain. Elle découpe l’information en blocs sémantiques (passages) et juge si chaque bloc répond à la requête. Plus votre contenu est structuré pour l’IA, plus chaque bloc devient extractible.
Les bonnes pratiques sont les suivantes :
- Hiérarchie de titres irréprochable (H2 et H3 logiques, pas de saut).
- Listes à puces ou numérotées pour les énumérations.
- Tableaux comparatifs pour toutes les comparaisons (chiffres, options, critères).
- Paragraphes courts (trois à quatre lignes maximum), une idée par paragraphe.
- Balisage Schema.org adapté : Article pour les contenus éditoriaux, FAQPage pour les sections questions-réponses, HowTo pour les guides, Product pour les fiches produit.
Les listicles, qui concentrent 21,9% des citations Perplexity, doivent leur performance à cette discrétisation extrême : chaque item est un bloc auto-suffisant que l’IA peut citer sans perdre le contexte.
Sourcer chaque affirmation avec des données vérifiables
Perplexity croise systématiquement ses sources pour réduire le risque d’hallucination. Un contenu non sourcé est perçu comme un risque, un contenu chiffré et sourcé comme une garantie.
Les bonnes pratiques :
- Chiffres précis avec leur source nommée et leur date de publication.
- Citations d’experts identifiés avec leur fonction et leur entité de rattachement.
- Liens sortants vers les études, rapports et institutions de référence (gouvernement, universités, organismes professionnels).
- Données propriétaires uniques : votre étude, votre sondage, vos cas clients chiffrés. Ces données qui n’existent nulle part ailleurs sur le web sont les plus différenciantes.
L’anti-pattern absolu : « des études montrent que » sans préciser laquelle. Ce type de formulation est ignoré par l’algorithme et fait baisser la crédibilité globale de la page pour les LLM.
Travailler son autorité topique sur l’ensemble du sujet
En tant qu’intelligence artificielle, Perplexity ne sélectionne pas une page isolée mais évalue la capacité d’un domaine à couvrir un sujet en profondeur. L’autorité topique se mesure par la densité de pages liées sur une même thématique et par la qualité du maillage interne entre ces pages.
Pour un sujet comme le référencement IA, cela suppose un cluster sémantique complet : une page pilier, des pages spoke par moteur, des pages de comparaison, et un maillage interne dense entre toutes.
À noter : Perplexity favorise les domaines de 10 à 15 ans à 26,16% de ses citations, ce qui crée une opportunité réelle pour les sites établis sans être historiques. L’ancienneté n’est pas l’argument décisif, contrairement aux AI Overviews de Google qui privilégient massivement les domaines de plus de 15 ans (49,21%).
Crawlabilité, laisser PerplexityBot accéder à votre site
Tous les leviers précédents supposent un prérequis : que Perplexity puisse réellement lire vos pages. Or de nombreux sites bloquent involontairement le crawler, ce qui rend toute optimisation inutile.
Le moteur utilise deux user-agents distincts. PerplexityBot parcourt le web pour alimenter l’index, Perplexity-User suit les liens cliqués par les utilisateurs depuis l’interface. Les deux doivent pouvoir accéder à votre site.
Trois vérifications à mener :
- Le fichier robots.txt ne doit contenir aucune directive Disallow qui bloque PerplexityBot. L’autorisation explicite est la pratique la plus saine.
- Les logs serveur doivent montrer des hits réguliers de PerplexityBot. Si vous publiez chaque semaine et que les logs ne montrent aucun passage du bot, il y a un blocage en amont à investiguer.
- Les protections anti-bot (Cloudflare Bot Fight Mode, WAF, pare-feu applicatif) bloquent souvent PerplexityBot par défaut, le considérant comme un scraper. Whitelistez-le explicitement dans votre console de sécurité.
Sans cette base technique, aucun travail éditorial ne produira de citation.
Mesurer votre visibilité sur Perplexity
Perplexity ne fournit pas de console équivalente à Google Search Console. Le monitoring se construit donc à la main, par croisement de plusieurs méthodes complémentaires.
La méthode manuelle, gratuite et immédiate, reste la plus fiable pour démarrer. On liste 10 à 20 prompts représentatifs du secteur, on les lance dans Perplexity, et on note systématiquement si la marque ou le site apparaît dans les sources. Un suivi mensuel avec captures d’écran permet de mesurer l’évolution. L’analyse des concurrents cités à votre place révèle les écarts à combler.
Le trafic referral dans Google Analytics permet de quantifier l’impact réel. Le filtre sur la source perplexity.ai isole les visites issues du moteur, et l’analyse des pages d’entrée identifie celles qui génèrent déjà des citations exploitables.
Les outils tiers GEO automatisent ce monitoring à grande échelle. Plusieurs solutions émergent sur le marché : Otterly AI, Profound, Peec AI, Ahrefs Brand Radar, Semrush AI Overview. Aucune ne dispose d’API officielle Perplexity, toutes opèrent par scraping de l’interface, ce qui implique une marge d’erreur et des coûts qui varient fortement selon le volume de prompts suivi.
Pour les marques qui veulent un suivi industrialisé sans gérer plusieurs outils, l’audit GEO WeComm couvre le suivi cross-plateforme avec un reporting unifié.
Questions fréquentes sur le référencement Perplexity
Mon site est bien positionné sur Google, pourquoi n’est-il pas cité par Perplexity ?
Seuls 11% des domaines cités par Perplexity le sont aussi par ChatGPT, et seulement 12% des URL citées par les IA figurent dans le top 10 Google. Les deux écosystèmes obéissent à des logiques de sourcing radicalement différentes.
Faut-il payer pour être cité par Perplexity ?
Non. L’abonnement Perplexity Pro permet de publier des pages dans la bibliothèque Perplexity, mais le référencement organique repose uniquement sur votre site et sur les sources tierces qui vous mentionnent.
Perplexity peut-il citer ma marque sans afficher de lien vers mon site ?
Oui. Les LLM analysent le texte des sources, pas leurs liens. Une mention non liée dans un média ou sur Reddit construit la même autorité d’entité qu’un backlink classique.
Le SEO classique est-il devenu inutile à l’ère de Perplexity ?
Non, il devient un socle. Le SEO assure que vos pages sont indexables, structurées et pertinentes. Le GEO ajoute la couche structure d’extraction, fraîcheur soutenue et présence multi-plateformes.
Une page Wikipedia est-elle indispensable pour être cité par Perplexity ?
Pas indispensable, mais fortement valorisante. Wikipedia est dans le top 3 des sources Perplexity et alimente une part importante des données d’entraînement des LLM.
Être référencé comme source par les moteurs IA, une stratégie à industrialiser
Apparaître dans les réponses Perplexity n’est plus une option pour les marques qui dépendent de la recherche en ligne. Le moteur cumule trois caractéristiques uniques : un volume de citations par réponse trois fois supérieur à ChatGPT, un taux de conversion six fois supérieur à Google organique, et une fiabilité factuelle saluée par les études académiques.
Les leviers d’optimisation existent et sont actionnables : pyramide inversée, fraîcheur soutenue, présence sur sources tierces, structure d’extraction, sourçage factuel, autorité topique. Tous reposent sur un changement d’approche éditoriale, pas sur des hacks techniques.
L’équipe GEO WeComm accompagne les marques dans la construction d’une stratégie multi-plateformes intégrant Perplexity, ChatGPT, Gemini et les AI Overviews de Google. Pour évaluer votre visibilité actuelle et identifier vos quick wins, prenez rendez-vous pour un audit GEO.